There’s a lot of debate in academic circles about what to call ChatGPT, the new Bing, Bard, and the set of new technologies that operate on similar principles.
“AI” or “Generative AI” are the terms preferred by industry. These terms are rightly criticized by many scholars in the fields of communications, science and technology studies, and even computer science as not only inaccurate (there is nothing “intelligent” about these systems in the way we usually think about intelligence; they have no understanding of the text they produce) but also as crass marketing ploys. These critics say these terms perpetuate a cynical “AI hype cycle” that’s simply intended to drive attention and investment capital to the companies that make these technologies—and deflect attention from their harms.
But I worry that the use of the term “AI hype cycle” isn’t doing the work its proponents think it is. My understanding is that those proponents hope the term will help people see through the breathless predictions of corporate interests and focus instead on the harms these interests are perpetrating in the present. I worry, however, that it reads, to the casual observer, as “nothing to see here.”
Surely that’s not the outcome we want.
“Chatbot” is another contender for the term of choice. And indeed it describes the kinds of interactions that most people are having with these technologies at the moment. But as Ted Underwood has said, “chatbot” doesn’t capture the range of appliacations that these technologies enable beyond chat through their APIs. They’re clearly more than the chatbots we used 20 years ago on AIM.
“LLM” (“Large Language Model”) seems to be preferred by academics (according to Simon Willison’s Mastodon poll), because it’s more accurate. LLM surely does a better job of describing of how these technologies work—by statistically predicting the next most likely word in a sequence—not by suggesting there’s any kind of deeper understanding at work.
But “LLM” has a serious problem. It’s an acronym, and therefore, it’s jargon. And therefore, it’s boring.
That leads me to my title’s second question: “What do we want our words to do?” Is the purpose of our words to asymptotically approach truth above and against all other considerations? Or do we want to draw people’s attention to that truth, even if the words we use are not quite as precise?
I have very mixed feelings about this. LLM is more accurate. But it’s also easy (for ordinary people, decision makers, regulators, politicians) to ignore. That is, it’s boring. I understand not wanting to amplify Silicon Valley’s hype, but we also don’t want to downplay the likely consequences of this technology. There has to be a way to tell people that something will be transformative (quite probably for the worse), and command their necessary attention, without being a cheerleader for it.
For example, the term “World Wide Web” was both completely hype and totally inaccurate when it was coined by Tim Berners Lee in 1989. But after the Internet being ignored by pretty much the entire world for 20 years, “the Web” surely captured the popular mind and brought the Internet to public attention.
Conversely, the terms “SARS-CoV-2” and “COVID-19” were both sober and accurate. But I worry that the clinical nature of the terms enabled people who were already predisposed to looking the other way to do so more easily. Calling it “Pangolin Flu” or “Raccoon Dog Virus” would have been less accurate, but they would have caught people’s attention. “Bird Flu,” “Swine Flu,” and Zika Virus, which have killed very few people in this country get a ton of attention relative to their impact. Surely terminology wasn’t the root cause of our society’s lazy response to the pandemic. But I don’t think it helped.
Now, I am NOT suggesting we develop intentionally misleading terminology just to get people’s attention. We can leave that to Silicon Valley. But I am suggesting that we think about what we want our words to do. Do we value accuracy to the exclusion of all other considerations? In that case, an acronym of some sort may be in order. Or do we also want people to pay attention to what we’re saying?
I don’t have a good suggestion for a specific term that accomplishes both goals (accuracy and attention), but I think we need one. And if we can’t come up with one that does both jobs, and the public conversation settles on “generative AI” or some other term coined by the industry, I don’t think we should spend too much time banging our heads against it or trying to push alternatives. We’ll be better served if our many and valid and urgent criticisms of “generative AI” and its industry are heard by people than by sticking earnestly with a term that lets people ignore us.
If there’s anything we should have learned from the past 25 years of the history of the internet it’s that academics “calling bullshit” is not a plan for dealing with unwanted technology outcomes.
Academics have two very deeply held and interrelated attachments. One is to accuracy and the truth. The other is to jargon. The one is good. The other can cause trouble. I hope in this case our attachment to the first doesn’t lead us to adopt a jargon-y language that enables people already predisposed to ignore the harms of the tech industry to do so more comfortably.
The following is a (more or less verbatim) transcript of a keynote address I gave earlier today to the Dartmouth College Teaching with Primary Sources Symposium. My thanks to Morgan Swan and Laura Barrett of the Dartmouth College Library for hosting me and giving me the opportunity to gather some initial thoughts about this thoroughly disorienting new development in the history of information.
Thank you, Morgan, and thank you all for being here this morning. I was going to talk about our Sourcery project today, which is an application to streamline remote access to archival materials for both researchers and archivists, but at the last minute I’ve decided to bow to the inevitable and talk about ChatGPT instead.
Dartmouth College Green on a beautiful early-spring day
I can almost feel the inner groan emanating from those of you who are exhausted and perhaps dismayed by the 24/7 coverage of “Generative AI.” I’m talking about things like ChatGPT, DALL-E, MidJourney, Jasper, Stable Diffusion, and Google’s just released, Bard. Indeed, the coverage has been wall to wall, and the hype has at times been breathless, and it’s reasonable to be skeptical of “the next big thing” from Silicon Valley. After all we’ve just seen the Silicon Valley hype machine very nearly bring down the banking system. In just past year, we’ve seen the spectacular fall of the last “next big thing,” so-called “crypto,” which promised to revolutionize everything from finance to art. And we’ve just lived through a decade in which the social media giants have created a veritable dystopia of teen suicide, election interference, and resurgent white nationalism.
So, when the tech industry tells you that this whatever is “going to change everything,” it makes sense to be wary. I’m wary myself. But with a healthy dose of skepticism, and more than a little cynicism, I’m here to tell you today as a 25-year veteran of the digital humanities and a historian of science and technology, as someone who teaches the history of digital culture, that Generative AI is the biggest change in the information landscape since at least 1994 and the launch of the Netscape web browser which brought the Internet to billions. It’s surely bigger than the rise of search with Google in the early 2000s or the rise of social media in the early 2010s. And it’s moving at a speed that makes it extremely difficult to say where it’s headed. But let’s just say that if we all had an inkling that the robots were coming 100 or 50 or 25 years into the future, it’s now clear to me that they’ll be here in a matter of just a few years—if not a few months.
It’s hard to overstate just how fast this is happening. Let me give you an example. Here is the text of a talk entitled (coincidentally!) “Teaching with primary sources in the next digital age.” This text was generated by ChatGPT—or GPT-3.5—the version which was made available to the public last fall, and which really kicked off this wall-to-wall media frenzy over Generative AI.
You can see that it does a plausible job of producing a three-to-five paragraph essay on the topic of my talk today that would not be an embarrassment if it was written by your ninth-grade son or daughter. It covers a range of relevant topics, provides a cogent, if simplistic, explanation of those topics, and it does so in correct and readable English prose.
Now here’s the same talk generated by GPT-4 which came out just last week. It’s significantly more convincing than the text produced by version 3.5. It demonstrates a much greater fluency with the language of libraries and archives. It correctly identifies many if not most of the most salient issues facing teaching in archives today and provides much greater detail and nuance. It’s even a little trendy, using some of the edu-speak and library lingo that you’d hear at a conference of educators or librarians in 2023.
Now here’s the outline for a slide deck of this talk that I asked GPT-4 to compose, complete with suggestions for relevant images. Below that is the text of speaker notes for just one of the bullets in this talk that I asked the bot to write.
Now—if I had generated speaker notes for each of the bullets in this outline and asked GPT’s stablemate and image generator, DALL-E, to create accompanying images—all of which would have taken the systems about 5 minutes—and then delivered this talk more or less verbatim to this highly educated, highly accomplished, Ivy League audience, I’m guessing the reaction would have been: “OK, seems a little basic for this kind of thing” and “wow, that was talk was a big piece of milktoast.” It would have been completely uninspiring, and there would have been plenty to criticize—but neither would I have seemed completely out of place at this podium. After all, how many crappy, uninspiring, worn out PowerPoints have you sat through in your career? But the important point to stress here is that in less than six months, the technology has gone from writing at a ninth-grade level to writing at a college level and maybe even more.
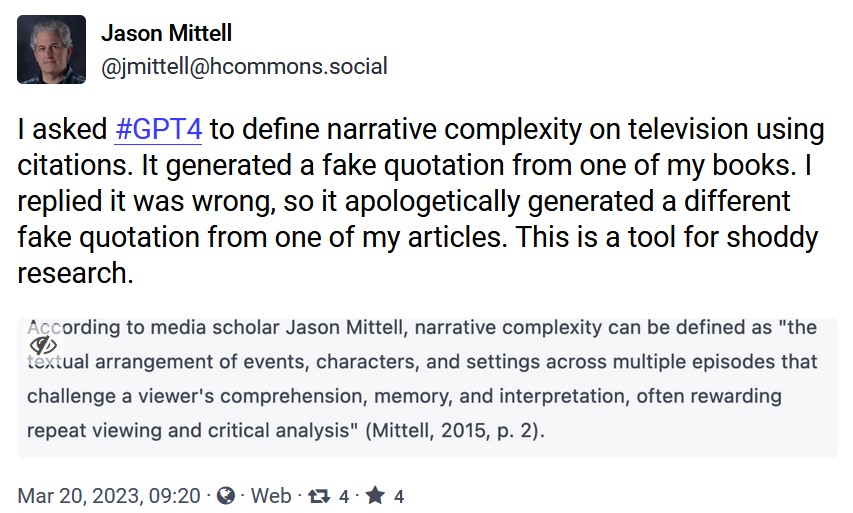
Much of the discourse among journalists and in the academic blogs and social media has revolved around picking out the mistakes these technologies make. For example, my good friend at Middlebury, Jason Mittell, along with many others, has pointed out that ChatGPT tends to invent citations: references to articles attributed to authors with titles that look plausible in real journals that do not, in fact, exist. Australian literary scholar, Andrew Dean, has pointed out how ChatGPT spectacularly misunderstands some metaphors in poetry. And it’s true. Generative AIs make lots of extremely weird mistakes, and they wrap those mistakes in extremely convincing-sounding prose, which often makes them hard to catch. And as Matt Kirschenbaum has pointed out: they’re going to flood the Internet with this stuff. Undoubtedly there are issues here.
But don’t mistake the fact that ChatGPT is lousy at some things for the reality that it’ll be good enough for lots, and lots, and lots of things. And based on the current trajectory of improvement, do we really think these problems won’t be fixed?
Let me give another couple of examples. Look at this chart, which shows GPT-3.5’s performance on a range of real-world tests. Now look at this chart, which shows GPT-4’s improvement. If these robots have gone from writing decent five-paragraph high school essays to passing the Bar Exam (in the 90th percentile!!) in six months, do we really think they won’t figure out citations in the next year, or two, or five? Keep in mind that GPT-4 is a general purpose model that’s engineered to do everything pretty well. It wasn’t even engineered to take the Bar Exam. Google CEO, Sundar Pichai tells us that AI computing power is doubling every six months. If today it can kill the Bar Exam, do we really think it won’t be able to produce a plausible article for a mid-tier peer reviewed scholarly journal in a minor sub-discipline of the humanities in a year or two? Are we confident that there will be any way for us to tell that machine-written article from one written by a human?
(And just so our friends in the STEM fields don’t start feeling too smug, GPT can write code too. Not perfectly of course, but it wasn’t trained for that either. It just figured it out. Do we really think it’s that long until an AI can build yet another delivery app for yet another fast-food chain? Indeed, Ubisoft and Roblox are starting to use AI to design games. Our students’ parents are going to have to start getting their heads around the fact that “learning to code” isn’t going to be the bulletproof job-market armor they thought it was. I’m particularly worried for my digital media students who have invested blood, sweat, and tears learning the procedural ins and outs of the Adobe suite.)
There are some big philosophical issues at play here. One is around meaning. The way GPT-4 and other generative AIs produce text is by predicting the next word in a sentence statistically based on a model of drawn from an unimaginably large (and frankly unknowable) corpus of text the size of the whole Internet—a “large language model” or LLM—not by understanding the topic they’re given. In this way the prose they produce is totally devoid of meaning. Drawing on philosopher, Harry Frankfurter’s definition of “bullshit” as “speech intended to persuade without regard for truth”, Princeton computer scientists Arvind Narayanan and Sayash Kapoor suggest that these LLMs are merely “bullshit generators.” But if something meaningless is indistinguishable from something meaningful—if it holds meaning for us, but not the machine—is it really meaningless? If we can’t tell the simulation from the real, does it matter? These are crucial philosophical, even moral, questions. But I’m not a philosopher or an ethicist, and I’m not going to pretend to be able to think through them with any authority.
What I know is: here we are.
As a purely practical matter, then, we need to start preparing our students to live in a world of sometimes bogus, often very useful, generative AI. The first-year students arriving in the fall may very well graduate into a world that has no way of knowing machine-generated from human-generated work. Whatever we think about them, however we feel about them (and I feel a mixture of disorientation, disgust, and exhaustion), these technologies are going to drastically change what those Silicon Valley types might call “the value proposition” of human creativity and knowledge creation. Framing it in these terms is ugly, but that’s the reality our students will face. And there’s an urgency to it that we must face.
So, let’s get down to brass tacks. What does all this mean for what we’re here to talk about today, that is, “Teaching with Primary Sources”?
One way to start to answer this question is to take the value proposition framing seriously and ask ourselves, “What kinds of human textual production will continue to be of value in this new future and what kinds will not?” One thing I think we can say pretty much for sure is that writing based on research that can be done entirely online is in trouble. More precisely, writing about things about which there’s already a lot online is in trouble. Let’s call this “synthetic writing” for short. Writing that synthesizes existing writing is almost certainly going to be done better by robots. This means that what has passed as “journalism” for the past 20 years since Google revolutionized the ad business—those BuzzFeed style “listicles” (“The 20 best places in Dallas for tacos!”) that flood the internet and are designed for nothing more than to sell search ads against—that’s dead.
But it’s not only that. Other kinds of synthetic writing—for example, student essays that compare and contrast two texts or (more relevant to us today) place a primary source in the context drawn from secondary source reading—those are dead too. Omeka exhibits that synthesize narrative threads among a group of primary sources chosen from our digitized collections? Not yet, but soon.
And it’s not just that these kinds of assignments will be obsolete because AI will make it too easy for students to cheat. It’s what’s the point of teaching students to do something that they’ll never be asked to do again outside of school? This has always been a problem with college essays that were only ever destined for a file cabinet in the professor’s desk. But at least we could tell ourselves that we were doing something that simulated the kind of knowledge work they would so as lawyers and teachers and businesspeople out in the real world. But now?
(Incidentally, I also fear that synthetic scholarly writing is in trouble, for instance, a Marxist analysis of Don Quixote. When there’s a lot of text about Marx and a lot of text about Don Quixote out there on the Internet, chances are the AI will do a better—certainly a much faster—job of weaving the two together. Revisionist and theoretical takes on known narratives are in trouble.)
We have to start looking for the things we have to offer that are (at least for now) AI-proof, so to speak. We have to start thinking about the skills that students will need to navigate an AI world. Those are the things that will be of real value to them. So, I’m going to use the rest of my time to start exploring with you (because I certainly don’t have any hard and fast answers) some of the shifts we might want to start to make to accommodate ourselves and our students to this new world.
I’m going to quickly run through eight things.
The most obvious thing we can do it to refocus on the physical. GPT and its competitors are trained on digitized sources. At least for now they can only be as smart as what’s already on the Internet. They can’t know anything about anything that’s not online. That’s going to mean that physical archives (and material culture in general) will take on a much greater prominence as the things that AI doesn’t know about and can’t say anything about. In an age of AI, there will be much greater demand for the undigitized stuff. Being able to work with undigitized materials is going to be a big “value add” for humans in the age of these LLMs. And our students do not know how to access it. Most of us were trained on card catalogs, in sorting through library stacks, of traveling to different archives and sifting through boxes of sources. Having been born into the age of Google, our students are much less good at this, and they’re going to need to get better. Moreover, they’re going to need better ways of getting at these physical sources that don’t always involve tons of travel, with all its risks to climate and contagion. Archivists, meanwhile, will need new tools to deal with the increased demand. We launched our Sourcery app, which is designed to provide better connections between researchers and archivists and to provide improved access to remote undigitized sources before these LLMs hit the papers. But tools like Sourcery are going to be increasingly important in an age when the kind of access that real humans need isn’t the digital kind, but the physical kind.
Moreover, we should start rethinking our digitization programs. The copyright issues around LLMs are (let’s say) complex, but currently Open AI, Google, Microsoft, Meta, and the others are rolling right ahead, sucking up anything they can get their hands on, and processing those materials through their AIs. This includes all of the open access materials we have so earnestly spent 30 years producing for the greater good. Maybe we want to start asking ourselves whether we really want to continue providing completely open, barrier-free access to these materials. We’ve assumed that more open meant more humane. But when it’s a robot taking advantage of that openness? We need a gut check.
AIs will in general just be better at the Internet than us. They’ll find, sort, sift, and synthesize things faster. They’ll conduct multi-step online operations—like booking a trip or editing a podcast—faster than us. This hits a generation that’s extremely invested in being good at the Internet, and, unfortunately, increasingly bad at working in the real world. Our current undergraduates have been deeply marked by the experience of the pandemic. I’m sure many of you have seen a drastic increase in class absences and a drastic decrease in class participation since the pandemic. We know from data that more and more of our students struggle with depression and anxiety. Students have difficulty forming friendships in the real world. There are a growing number of students who choose to take all online classes even though they’re living in the dorms. This attachment to the virtual may not serve them well in a world where the virtual is dominated by robots who are better than us at doing things in the digital world. We need to get our students re-accustomed to human-to-human connections.
At the same time, we need to encourage students to know themselves better. We need to help them cultivate authentic, personal interests. This is a generation that has been trained to write to the test. But AIs will be able to write to the test much better than we can. AIs will be able to ascertain much better than we can what they (whomever they is: the school board, the college board, the boss, the search algorithm) want. But what the AI can’t really do is tell us what we want, what we like, what we’re interested in and how to get it. We need to cultivate our students’ sense of themselves and help them work with the new AIs to get it. Otherwise, the AI will just tell them what they’re interested in, in ways that are much more sophisticated and convincing than the Instagram and TikTok algorithms that are currently shoving content at them. For those of us teaching with primary sources this means exposing them to the different, the out of the ordinary, the inscrutable. It means helping them become good “pickers” – helping them select the primary sources that truly hold meaning for them. As educators of all sorts, it means building up their personalities, celebrating their uniqueness, and supporting their difference.
I think we also need to return to teaching names and dates history. That’s an unfashionable statement. The conventional wisdom of at least the last 30 years is that that names, dates, and places aren’t that important to memorize because the real stuff of history are the themes and theories—and anyway, the Google can always give us the names and dates. Moreover, names and dates history is boring and with the humanities in perpetual crisis and on the chopping block in the neoliberal university, we want to do everything we can to make our disciplines more attractive. But memorized names, and dates, and places are the things that allow historians to make the creative leaps that constitute new ideas. The biggest gap I see between students of all stripes, including graduate students, and the privileged few like me who make it into university teaching positions (besides white male privilege) is a fluency with names, dates, and places. The historians that impress most are the ones who can take two apparently disconnected happenings and draw a meaningful connection between them. Most often the thing that suggests that connection to them is a connected name, date, place, source, event, or institution that they have readily at hand. Those connections are where new historical ideas are born. Not where they end, for sure, but where they are born. AI is going to be very good at synthesizing existing ideas. But it may be less good at making new ones. We need students who can birth new ideas.
Related to this is the way we teach students to read. In the last 20 years, largely in response to the demands of testing, but also in response to the prioritization of “critical thinking” as a career skill, we’ve taught students not to read for immersion, for distraction, for imagination, but for analysis. Kids read tactically. They don’t just read. In many cases, this means they don’t read at all unless they have to. Yet, this is exactly how the AI reads. Tactically. Purely for analysis. Purely to answer the question. And they’ll ultimately be able to do this way better than us. But humans can read in another way. To be inspired. To be moved. We need to get back to this. The imaginative mode of reading will set us apart.
More practically, we need to start working with these models to get better at asking them the right questions. If you’ve spent any time with them, you’ll know that what you put in is very important in determining what you get out. Here’s an example. In this chat, I asked GPT-3.5, “How can I teach with primary sources.” OK. Not bad. But then in another chat I asked, “Give me a step-by-step plan for using primary sources in the classroom to teach students to make use of historical evidence in their writing” and I followed it up with a few more questions: “Can you elaborate?” and “Are there other steps I should take?” and then “Can you suggest an assignment that will assess these skills?” You’ll see that it gets better and better as it goes along. I’m no expert at this. But I’m planning on becoming one because I want to be able to show our students how to use it well. Because, don’t fool yourselves, they’re going to use it.
Finally, then, perhaps the most immediate thing we can do is to inculcate good practice around students’ use of AI generated content. We need to establish citation practices, and indeed the MLA has just suggested some guidance for citing generative AI content. Stanford, and other universities, are beginning to issue policies and teaching guidance. So far, these policies are pretty weak. Stanford’s policy basically boils down to, “Students: Don’t cheat. Faculty: Figure it out for yourselves.” It’s a busy time of year and all, but we need urgently to work with administration to make these things better.
I’m nearly out of time, and I really, really want to leave time for conversation, so I’ll leave it there. These are just a couple of thoughts that I’ve pulled together in my few weeks of following these developments. As I’ve said, I’m no expert in computer science, or philosophy, or business, but I think I can fairly call myself an expert in digital humanities and the history of science and technology, and I’m convinced this new world is right around the corner. I don’t have to like it. You don’t have to like it. If we want to stop it, or slow it down, we should advocate for that. But we need to understand it. We need to prepare our students for it.
At the same time, if you look at my list of things we should be doing to prepare for the AI revolution, they are, in fact, things we should have been (and in many cases have been) doing all along. Paying more attention to the undigitized materials in our collections? I’m guessing that’s something you already want to do. Helping students have meaningful, in-person, human connections? Ditto. Paying more attention to what we put online to be indexed, manipulated, sold against search advertising? Ditto. Encouraging students to have greater fluency with names, dates, and places? Helping them format more sophisticated search queries? Promoting better citation practice for born-digital materials and greater academic integrity? Ditto. Ditto. Ditto.
AI is going to change the way we do things. Make no mistake. But like all other technological revolutions, the changes it demands will just require us to be better teachers, better archivists, better humans.
I’m brand new to Mastodon. Many of us are. This might suggest that we shouldn’t have opinions. But I think the opposite is true. If Mastodon is truly a decentralized platform, if it’s truly designed to support distinctive communities and their distinctive needs, then we, as a community of humanists, should decide how we’re going to use it. We should start doing it now, before it gets away from us.
Deciding how we want to use it—what Mastodon will mean to us—means not putting too much stock in the “norms” and “rules” that other communities have established on the site. That is not to say we should be bulls in the porcelain shop (or as Shawna Ross tooted, we “don’t want to go all Kool-Aid man”), or that we should be disrespectful to other, more established communities and their needs and concerns. As always, we should approach our work, our tools, and our public engagements with humility. But it’s legitimate for us to use the technology to meet our needs and concerns, needs and concerns that have for too long gone unmet by Twitter, needs and concerns that may not be the same as other, older Mastodon communities.
In that spirit, here are a few early thoughts on how I think we should use Mastodon to build a supportive, inclusive, interesting, and useful thing for the humanities community.
First, you should join a server (e.g. hcommons.social) where a lot of other humanists can be found, and spend most of your time in your “local” or “community” timeline/tab. It is all well and good to follow people from other servers, and you should keep up with friends and happenings in those other places. But if you’re on the right server, your main source of serendipity, delight, information, and community will come from that local timeline. If your server’s local timeline is not delivering those things, find another server.
Second, and relatedly, you should mostly avoid the “the fediverse” (i.e. the feed of posts aggregated from across Mastodon’s servers found in the “federated” or “all” tab in your app). It seems to me that in time this aggregated feed will just reproduce Twitter, in all its disorienting chaos and vitriol. It probably won’t be quite so bad because it won’t have an algorithm pushing ads and outrage down your throat. But there’s bound to be plenty of ugly distraction nonetheless.
Third, and this is bound to be controversial, but don’t be too fussed about content warnings (CW’s), except insofar as you think members of your local server will appreciate them. That is, I wouldn’t be too worried about sticking to the “norms” or “best practices” that other, earlier communities on Mastodon have established. I appreciate that these norms are in place because Mastodon has been a refuge for marginalized BIPOC, LGBTQ+, and other communities—and I think we want to be a refuge for members of those communities too. But we shouldn’t simply adopt the practices of the early adopters because they say we should. We should decide the ways in which we want to use the tools Mastodon gives us to support our aims, including, but not limited to, our aims of diversity, equity, and inclusion. So, for example, I think it’s totally fine to use the CW feature to truncate and expand a long toot. One of the distinctive features of the humanities community is its tolerance for difference. Another is its longwindedness. It’s OK to use the tool to support both things!
Fourth, let’s start blogging again. One of the great things about early #DH Twitter was that we were all still blogging. Twitter became a place where we could let a wider audience know that we blogged something and then support a discussion around that something that was more freeflowing than the blog’s own comments thread could support. Let’s bring that practice back! One easy step would be to stop posting long, narrative threads (i.e. tweets “1/27”) to social media. Instead just post a title, a one sentence description, a link to your post with a #blogpost hashtag, and an invitation to discuss. If we could use Mastodon to reinvigorate the culture of humanities blogging, that would be an amazing success.
Fifth, keep politics to a minimum. It’s not that we should never talk about politics, but reworking takes that one can get elsewhere in the media (cable news, the op-ed pages, Twitter, etc.) isn’t going to make this a nicer place to be. If you’re going to get political, clearly tie it to your research, teaching, public humanities practice, or something else that connects you to the community that your local server is intended for. Otherwise, set up another account on another, more clearly political server, and post there.
Those are just some early thoughts. I’ll probably follow up in the next week or so with some more. In the meantime, I’d love to hear yours.
I’ve spent the last 24 hours thinking about and responding to Mark Matienzo’s recent post about Sourcery and its response on social media. I’ve enjoyed engaging in the concerns Mark raises and I’ve learned a lot from the conversation it has spurred. Everything Mark wonders and worries about in connection with Sourcery are things we are actively questioning ourselves. It’s the reason we held a series of workshops with the archives profession this past fall and it’s the reason we’re working with a set of institutional partners to pilot Sourcery while it’s still under active development — so that we can address these questions and concerns in conversation with the community and have those conversations inform the functionality of the application.
These conversations, however, have demonstrated to me that there’s a bit of a misperception circulating, not so much about the app itself, but about the way in which we aim to develop it, a misperception that’s born, I think, more of a learned skepticism of Silicon Valley and university austerity politics than it has to do with a real look at the way in which we’re actually going about things.
The first thing to say is that we don’t begrudge archivists their skepticism. We share it. A decade that’s seen democracy undermined by social media and labor undermined by “gig economy” apps has made us justifiably skeptical of technology. Likewise, a decade or more of austerity budgets has made archivists justifiably skeptical of “external” “solutions.” But Sourcery is not “external” to these concerns: Greenhouse Studios is based in the library of a state university and staffed by unionized librarians and faculty members. We’re well familiar with austerity budgets, believe me. And we’re not promising a “solution.” What we want to do is engage the field — both researchers and archivists — in a conversation about how some of the technologies of the past decade might be retrofitted to expand access to archival sources.
Thanks @anarchivist, for raising these concerns. We share then, and we're certainly not looking to exploit anyone. Let me add a little context. 1/
Sourcery is not a stealth operation to undermine or “disrupt” archival labor or paid researchers like Uber was a stealth operation to undermine taxi drivers. If it were, we wouldn’t have released a roadmap and half-baked app to the community for comment and reflection in a series of workshops, talks, and pilot projects with institutional partners. (We are very much still in our “planning” phase.) Informed by nearly 20 years of building open source, not-for-profit, community-based software systems for libraries and scholarship, our purpose (and the explicit terms of our funding) has always been to engage the community in a process of conversation and co-creation around alleviating the (sometimes cross-cutting!) pressures of archivists and researchers and then to build something that responds to those pressures. Some may disagree, but I don’t think that just because a technology has been used badly by some means that it’s necessarily bad. Certainly Uber has used peer-to-peer technologies in some very bad ways. But GoFundMe has used peer-to-peer technology in some very good ways (the broader SNAFU that is our healthcare system notwithstanding). Our aim is to work with all the relevant groups to make sure we do the good things and avoid the bad things.
If we haven’t made that clear, that’s on me. This post certainly isn’t intended as defense against unwanted critique or tough conversations.
At the same time, it does offer a challenge to archivists. Just as its incumbent on us to understand the challenges archivists face and to work to meet those challenges in our outreach and our software, the tough conversations must also include an acknowledgment of the fact that the current systems for getting remote access to documents isn’t very good and that it hasn’t kept up with either the possibilities of the available technology or the needs of diverse researchers. The process for requesting remote assistance hasn’t really changed since the advent of email and the simple web forms of the mid-1990s (although the pandemic has complicated that picture). We should acknowledge that existing systems of remote access to non-digitized sources create confusion for researchers who need to learn a new system for every repository they encounter. They create disjointed reference workflows for archivists that can be hard to monitor, allocate within teams, track, record, and report. And their failings cause more visits to the reading room than are probably strictly necessary or desirable for either archivists or researchers. By no means do we want to replace the necessary, sustained, intellectually fruitful in-person exchanges between archivists and researchers and the mutual journeys of discovery that take place in the reading room. But we do aim to replace the unnecessary ones.
Here it’s crucial to point out the perhaps under-appreciated fact that in-person visits are available to only a small subset of the researching population — that is, those with the money and flexibility to make a trip. The same is true of the informal networks whereby friends-of-friends and colleagues’ grad students go get stuff for scholars. Travel and professional networks are a privilege of the rich and well-connected, graduate student labor is often exploited for these purposes, and the “gift economy” whereby junior scholars do uncompensated service on behalf of more senior scholars is insidious. Whether intentional or not, current systems that place an enormous premium on the in-person visit end up providing access on extremely unequal terms. Emily Higgs correctly pointed out on Twitter that Sourcery is responsible for the ill effects of its service, whatever its good intentions. It’s likewise true that—given the possibility of change—the archives profession will be at least partly responsible for the ill effects of the status quo, whether it ever intended them or not. Sourcery runs the risk of creating new inequalities, for sure. But sticking with a status quo that privileges the in-person visit even when it’s not strictly necessary — a status quo that privleges rich scholars and ones with fancy connections and ones with grad students to exploit — runs the risk of perpetuating old inequalities. Not doing something to address the situation is an affirmative choice. That something doesn’t have to be Sourcery … but we should be honest that some things should change.
I’m seriously not trying to call anybody out. I’m just saying that researchers, archivists, digital humanists, software developers, and their funders and administrators need to work together if we’re going to expand access in ways that neither create new inequalities nor perpetuate old ones. That’s the conversation we want to have, and I know the archival profession wants to have, and I’m glad Sourcery is causing it.
During the depths of the lockdown in March, I imagined a course for our times that would be completely free of digital technology. I was frustrated with administrative rhetoric that seemed to put means ahead of ends in stressing how best to “go online” over how best to “deliver a quality distance education” regardless of the tools. Like the workman with a hammer for whom all the world’s a nail, the administration had its WebEx and Blackboard licenses and, by Jove, we would use them! Everyone was just trying to do their best, of course, and many administrators and especially experienced educational technologists (who understand better than anyone that delivering quality education over the Internet isn’t just a simple matter of “putting it online”) were just as uneasy with the whole conversation as I was.
In my frustration and reactionary pose, I thought about what it would look like to “go offline” and deliver a distance learning experience without any digital tools at all. Remembering that the humanities have a centuries-long history of scholarly correspondence — of teaching and mentorship using the tools of pen and paper and the networking technology of the post office or courier — I imagined my first-year graduate readings seminar as a correspondence course conducted completely via the United States Postal Service. It would be a return to the early-20th century correspondence course or even to the culture of Greek and Roman philosophical letters that animated Cicero and St. Paul.
In the end, I decided this plan would be untenable. For one thing, it wouldn’t have been fair to my new graduate students. The first semester of grad school is disorienting enough, even more so this year, and my students didn’t deserve being subjects to some kind of retrotech experiment by their professor. It also didn’t help that in August it seemed like the President was trying to sink the USPS to aid his re-election.
But I kept the basics of the idea, and I have been teaching my DMD 5010: Digital Culture readings seminar as a correspondence course of sorts. Each week, the students are assigned a pen pal and spend the week corresponding by email about the assigned reading. Each pair copies me, along with another student who has been picked as the discussion leader, on their emails. In class the next week, the discussion leader summarizes the correspondence and kicks off the class, which takes place by video conference.
Maybe it’s the choice of books. Maybe it’s just these particular students. But I have never had such engaged, informed, and provocative seminar discussions in my many years of teaching. Here I have a group of students whom I’ve never met in person, and who, to my knowledge, have never met each other in person, and each week our video sessions run over time with informed, enthusiastic, creative discussion and debate. I barely have to say a word to keep the conversation running.
I suspect this unprecedented (for me) level of engagement is due to what we call our “letter writing.” Each student is responsible not to me, but to their pen pal, to do the reading, to think hard about its meaning, and to draw new meanings from their partner’s work. They ask authentic questions. And in addition to being deeply in conversation with the readings, the students’ letters are funny, full of personality, and full of care for their fellow students in these difficult times. The fact that each student has, at some point in the semester, engaged in authentic correspondence with every other student, has created a group dynamic which honors the intellectual strengths and weaknesses of each member of the group and the ups and downs of their work and home life. It’s great, and I think it justifies my initial impulse to meet the challenges of distance learning not with more tech, but with less. I may even teach it the same way (hopefully with a few scheduled in-person meet ups along the way) even after COVID-19 is blessedly behind us.
Since the 1970s, scholars in fields as varied as sedimentology, ornithology, sociology, and philosophy have come to understand the importance of self-organizing systems, of how higher-order complexity can “emerge” from independent lower-order elements. Emergence describes how millions of tiny mud cracks at the bottom of a dry lake bed form large scale geometries when viewed at a distance, or how water molecules, each responding simply to a change in temperature, come to form the complex crystalline patterns of a snowflake. Emergence describes how hundreds of birds, each following its own, relatively simple rules of behavior, self-organize into a flock that displays its own complex behaviors, behaviors that none of the individual birds themselves would display. In the words of writer Steven Johnson, emergence describes how those birds, without a master plan or executive leadership, go from being a “they” to being an “it.” In other words, emergence describes a becoming.
We, too, form emergent systems. Emergence describes how a crowd of pedestrians self-organizes to form complex traffic flows on a busy sidewalk. Viewed close-up, each pedestrian is just trying to get to his or her destination without getting trampled, reacting to what’s in front of him or her according to a set of relatively simple behavioral rules—one foot in front of the other. Viewed from above, however, we see a structured flow, a river of humanity. Acting without direction, the crowd spontaneously orders itself into a complex system for maximizing pedestrian traffic. The mass of individual actors has, without someone in charge, gone from being an uncoordinated “they” to an organized “it.”
Emergent approaches to scholarly communication have long been an interest of mine, although I’ve only recently come to think of them this way. My first experiment in the emergent possibilities of radical collaboration took the form of THATCamp—The Humanities and Technology Camp—an “unconference” that colleagues at the Roy Rosenzweig Center for History and New Media and I launched in 2008. Instead of a pre-arranged, centrally-planned conference program, THATCampers set their own agendas on the first morning of the event, organizing around the topics that happen to be of most interest to most campers on that day. Another example is Hacking the Academy, a collaboration with Dan Cohen, which posed an open call for submissions to the community of digital humanists on a seven-day deadline. From the patterns that emerged from the more than 300 submissions we received—everything from tweets to blog post to fully formed essays—we assembled and published an edited volume with University of Michigan Press. A final experiment with this emergent approach was a project called One Week | One Tool. This Institute for Advanced Topics in Digital Humanities brought together a diverse collections of scholars, students, programmers, designers, librarians, and administrators to conceive, build, and launch an entirely new software tool for humanities scholarship. Participants arrived without an idea of what they would build, only the knowledge that the assembled team would possess the necessary range of talent for the undertaking. They began by brainstorming ideas for a digital project and proceeded to establish project roles, iteratively design a feature set, implement their design, and finally launch their product on day seven.
The Greenhouse Studios design process similarly provides a space for emergent knowledge making. Greenhouse Studios is interested in what new knowledge might emerge when we allow academic communities to self-organize. We are asking what kinds of higher-order complexities arise when teams of humanists, artists, librarians, faculty, students, and staff are given permission to set and follow their own simple rules of collaboration. This mode of work stands in strong rebuke to what I would call the “additive” model of collaboration that draws resources and people together to serve faculty member-driven projects. Instead, Greenhouse Studios provides its teams with the conditions for collaboration—diversity and depth of thought and experience, time apart, creative tools and spaces—and lets them set their own projects and own roles. At Greenhouse Studios, we’re running an experiment in radical collaboration, exploring what happens when you remove the labor hierarchies and predetermined workplans that normally structure collaborative scholarly projects, and instead embrace the emergent qualities of collaboration itself.
I firmly believe the case for the humanities is best made on its own terms. Rather than bending pretzel-like to explain how the humanities contribute to the prevailing values of techo-industrial capitalism, we should argue first and foremost for the humanities as good in their own right. We should be strong in our conviction that the social and moral goods produced by the humanities are of equal value to the economic goods produced by science, technology, and business. That said, it is sometimes pragmatic to show that even when measured by the standards of science, technology, and business, the humanities are extremely valuable. When arguing our case to decision makers who are themselves members of the STEM fields (e.g. your Dean or Provost) or who have become convinced of the central importance of STEM in the 21st century economy (e.g. legislators or members of your board of visitors), it is often more persuasive to do so on their preferred turf.
One way to do this is to argue from primary data that show the direct economic benefits of arts and humanities in our communities. The American Academy’s Humanities Indicators project is a good place to look for this kind of evidence. Another way is to refer decision makers to the frequent statements of prominent members of the tech community who have spoken out in support of the humanities education and humanities skills as useful in the tech economy. Good examples of this kind of secondary evidence are Mark Cuban’s recent statements warning students off finance and computing in favor of liberal arts; David Kalt’s assertion that “individuals with liberal arts degrees are by far the sharpest, best-performing software developers and technology leaders”; and the example of Slack co-founder Stewart Butterfield’s crediting of his philosophy degree for his success. I’m sure you’ve seen more examples of this type, which I’d love to collect in the comments section below.
Quoting STEM and business types back to themselves is sometimes the most effective way to argue our worth. It’s one thing to say your work is important, it’s another to show that the people your audience respects most say your work is important. It may not be the case we want to make, but sometimes it’s the case we have to make.
One of the things I try very hard to do in my DMD 2010 “History of Digital Culture” class is to teach students that their technology choices are not inevitable nor even determined primarily by what’s “best,” but rather that their technology choices are values choices, reflections of their ethical commitments and those of the communities that create and use those technologies.
When the University of Connecticut’s UITS (University Information Technology Services) made a choice not to renew it’s Adobe Creative Cloud site license, my students correctly judged that this was a values choice about the relative importance the higher administration places on artistic work at the university. The decision not to support software for artists, while at the same time maintaining support for software for, say, engineers, is a statement about how the university values different kinds of work on campus. I was pleased that the students immediately saw that this wasn’t just a choice about the quality of the software or even its cost, but about the intellectual commitments and identity of the university. What the students didn’t so easily grasp, however, was that the controversy over the Adobe suite also reflects on the values choices of the students, on the values choices that digital artists have made over many years to put the Adobe suite and other expensive, proprietary, closed-source software packages at the center of their creative practice, which in turn stems from set of larger choices artists have made vis à vis our prevailing copyright regime.
Artists have largely chosen think about copyright a something that exists to protect them and their work, and they have generally supported our ever-stricter copyright regime. Moving from a humanities and social sciences faculty to a fine arts faculty when I came to UConn from George Mason in 2013, I was struck by how poorly my storm-the-barricades, anti-copyright, open access agenda went over with my colleagues. Not that anyone really cared, but it was apparent from the beginning that I was coming at conversations that touched upon intellectual property (for example, a conversation about making faculty syllabi freely available on the web) from one side of the fence and they were coming at them from the other. Indeed, UConn’s School of Fine Arts offers a course on copyright for artists called Protecting the Creative Spirit: The Law and the Arts, which is taught by two lawyers. You can tell from the title of the course where its sympathies lie.
My DMD 2010 students (most of whom are freshman and sophomores studying in the department of Digital Media & Design which resides within the School of Fine Arts) are no exception. When I teach the unit on copyright, the first question I ask the class is, “What is the purpose of copyright.” Inevitably, students answer with some version of “to keep people from ripping you off.” My next move is to put the copyright clause of the Constitution up on the overhead and explain to them that, in fact, the purpose of copyright is to “Promote the Progress of Science and useful Arts” and that protecting an author’s exclusive rights for a limited term is simply a means to an end.
What is more, I tell them that the ever-stricter copyright regime we live with today wasn’t really designed to protect artists artists at all, although some may have used and benefited its protections. Instead, it was designed by and for big corporations, and it does a much better job of protecting those corporations than it does of protecting individual artists. It is true that many of these corporations employ artists (several former DMD 2010 students are now working for Disney), but those artists’ works are works for hire. The works may be protected by copyright law, but they are protected to the benefit of the employer, not the employee.
It is telling that the feelings of outrage and abandonment regarding the UITS Adobe announcement weren’t evenly distributed among my students. Digital Media & Design students at UConn choose from six different “concentrations,” electing to focus on either 2D animation/motion graphics; 3D animation; game design and development; web design and development; digital media business strategies; or digital culture, learning, and advocacy. (Students from all concentrations are required to take DMD 2010.) Especially hard hit by the news were the 2D/motion graphics students, for whom Adobe After Effects sits at the heart of their practice and for which there really isn’t a substitute, commercial or open source. Letting the Adobe license lapse was basically going to kill their creative practice, or, at the very least, put them out several hundred dollars.
My web design and development students, on the other hand, felt sympathy for their colleagues, but were pretty blasé about the whole thing. For them, letting the Adobe license lapse wouldn’t really change anything. The Adobe corporation has very little leverage over a web developer. To drive the point home, I challenged these web development students to think of a single piece of software that, if taken away from them, would affect their practice in any significant way. A few came up with TCP/IP, but quickly corrected themselves: TCP/IP is a protocol not a piece of software and is an open standard in any case. Apache was another, but, again, it’s open source, and there are serviceable alternatives. Certainly, they couldn’t name a corporation that exists that could raise its prices and bring their web development work to a halt in the way that Adobe was threatening to stop the work of our motion graphics artists. The difference, of course, is that our web developers rely on an open source technology stack and our motion graphics artists rely on proprietary software protected by a copyright law that was written in part by the very companies that produce it. Our web developers are not captive to copyright. Our motion graphics artists are.
Far from protecting artists, this is the best example I have of how our overly restrictive copyright regime harms artists. Rather than teaching our students how to situate their creative practice within a framework of intellectual property protection and thereby reinforce a copyright regime that wasn’t put in place for them in the first place, we should be encouraging our students to resist this regime. We should be teaching them to advocate for open access and open source software. In the longer term, we should be helping them to develop open source and open access alternatives themselves. This is an especially important message for my digital media and design students who, with their considerable skills, will be in a position to effect the longer term project of building the open source tools that will be necessary to free artists’ creative practice from propriety software. In the long term, maybe the very long term, this is the only way we can keep digital artists from being held hostage to corporations as Adobe held my students hostage this semester.
Fortunately, we’ve sorted out the Adobe license issue for now by cutting a licensing deal (shall we call it a hostage negotiation?) apart from UITS for students enrolled in the School of Fine Arts. For now, our students are safe. But only for now. You can bet I’ll be screaming this example over the fence at my colleagues in the School of Fine Arts the next time we talk about copyright.
Looking down the page, it seems I haven’t posted here on the ol’ blog in nearly three years. Not coincidentally, that’s about when I started work on the initiative I’m pleased to announce today. It was in the fall of 2014 that I first engaged in conversations with my UConn colleagues (especially Clarissa Ceglio, Greg Colati, and Sara Sikes, but lots of other brilliant folks as well) and program officers at the Andrew W. Mellon Foundation about the notion of a “scholarly communications design studio” that would bring humanist scholars into full, equal, and meaningful collaboration with artists, technologists, and librarians. Drawing on past experiences at RRCHNM, especially One Week | One Tool, this new style digital humanities center would put collaboration at the center of its work by moving collaboration upstream in the research and publication workflow. It would bring designers, developers, archivists, editors, students, and others together with humanist faculty members and at the very outset of a project, not simply to implement a work but to imagine it. In doing so, it would challenge and level persistent hierarchies in academic labor, challenge notions of authorship, decenter the faculty member as the source of intellectual work, and bring a divergence of thought and action to the design of scholarly communication.
A planning grant from Mellon in 2015 allowed us to explore these ideas in greater depth. We explored models of collaboration and project design in fields as disparate as industrial design, engineering, theater, and (of course) libraries and digital humanities. We solicited “mental models” of good project design from diverse categories of academic labor including students, faculty members, archivists, artists, designers, developers, and editors. We visited colleagues around the country both inside and outside the university to learn what made for successful and not-so-successful collaboration.
The result of this work was a second proposal to Mellon and, ultimately, the launch this week of Greenhouse Studios | Scholarly Communications Design at the University of Connecticut. Starting this year with our first cohort of projects, we will be pioneering a new, inquiry-driven, collaboration-first model of scholarly production that puts team members and questions at the center of research and publication rather than the interests of a particular faculty member or other individual. Teams will be brought together to develop answers to prompts generated and issued internally by Greenhouse Studios. Through a facilitated design process, whole teams will decide the audience, content, and form of Greenhouse Studios projects, not based on any external expectations or demands, but according to their available skills and resources, bounded by the constraints they identify, and in keeping with team member interests and career goals.
Stay tuned to see what these teams produce. In the meantime, after three long years of getting up and running, I plan to be posting more frequently in this space, from my new academic home base, Greenhouse Studios.
Last week I had the pleasure of serving as facilitator at the first Mellon-funded Triangle Scholarly Communication Institute (SCI) in Chapel Hill. For the better part of the week five diverse teams of scholars, librarians, developers, and publishers came together to advance work on projects addressing challenges ranging from data visualization and virtual worlds to providing computational research access to large newspaper collections to building curriculum resources for understanding Sikh religion and culture. It was a great week.
At the end of the event, the teams were each asked to deliver an “elevator pitch” for their project. Quite what this pitch should entail remained something of an open question going into the final day of the Institute, so the project organizers, me included, came up with the following structure, which we shared with the teams the evening before their presentations, on the spot:
“The What” What is your project? What needs does it meet or problems does it solve? How does it meet those needs/solve those problems?
“The So What?” Why does this project matter? What are its implications for the field of scholarly communication? What are its broader impacts for the way scholarship is produced and disseminated?
“The What Next?” What is your plan for implementing your project? What will be the first thing/s you do to advance your project when you leave SCI? How will you maintain working communication between team members in the weeks and months ahead?
It occurs to me that this is a formulation that I have used in many elevator pitches, planning documents, grant proposals, etc. over the years and that it may be useful to others. When you’re trying to convince people to do something, buy something, or support something, these are generally the things they will want to know — What am I buying? Why should I want it? How will you deliver it? Most RFPs, grant guidelines, and the like are variations on this theme. So, when you’re at the early stages of planning a new project, where ever it may end up, this structure may be a useful starting point.


{kind=link}