
Making an AI Frontend for ArchivesSpace
In my last newsletter, I argued that we should meet “Big AI’s” harms not with idle protest or rejection, but by actively engaging with the tools and building better alternatives. I built AcadiMeet in this spirit. Though I really think we need something better than Doodle for academic meeting scheduling, that’s not the reason I started work on the tool. I built it because I wanted to know more about what AI does well and what it does poorly in order to be able to actively engage its affordances and harms on my own terms and in keeping with my values.
Coming off this experience and intrigued by Dan Cohen’s experiments with MCPs at the Northeastern University Libraries, for my next project I decided to try to implement an AI application myself. Sourcery (the remote document delivery application I direct in collaboration with colleagues at UConn and Digital Scholar) was a natural jumping off point, and over the past week or so I’ve prototyped an AI “reference interview assistant” and scanning request workflow for institutions that use ArchivesSpace.
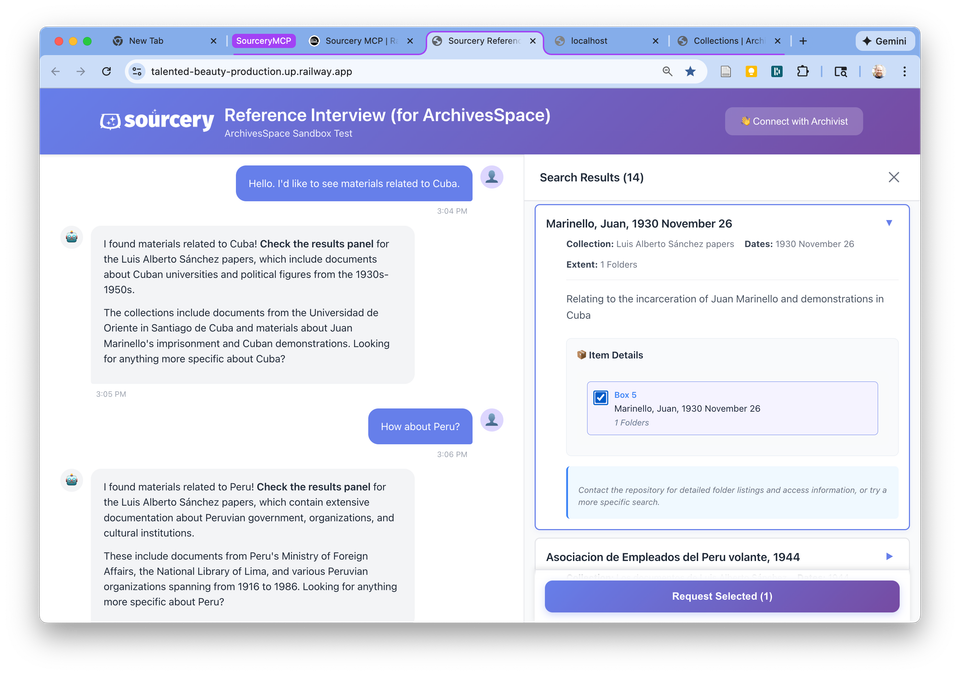
The new application works by letting you ask natural language questions directly of an archival finding aid, which then talks back to you, asking follow up questions until it finds items in the collection you may be interested in. Then, once you’ve found something you’d like to see, it places a scanning request through Sourcery. At any time in the process, or if the AI hits a dead end, you can hit a button to contact a real archivist.
To make it, I first built an MCP server for the ArchivesSpace API that enables Claude (or another LLM) to build answers to user queries based on data from an ArchivesSpace finding aid. Next I built a prompt file/interview template based on the ALA Guidelines for Behavioral Performance of Reference and Information Service Providers and on a handful of articles from the American Archivist about good reference interview practice. Then I built a web frontend that interviews the user, finds folder-level results from the ArchivesSpace collection based on their answers, and pushes metadata for the user’s selected folders into the standard Sourcery scanning request workflow.
The current prototype uses the ArchivesSpace sandbox, mainly because I wanted to start with a generic implementation that could be customized for any institution. As it stands, as long as I have an API key, I can pretty much point it at any ArchivesSpace instance simply by changing a few lines of code. There's also a placeholder in the interview logic for individual institutions’ use policies and unique processes. I’m also pretty close to getting model swapping working, which would make it easy to switch from Claude to something open source and/or self-hosted (e.g. Mistral).
What’s been really eye opening here is just how many opportunities there are for these kinds of experiments and local implementations of AI. When all you see is the chat box on the Gemini or ChatGPT homepage, AI can seem open ended to the point of bafflement. But when you see what it can do in a local context, operating on a local API and on data that’s really in your wheelhouse, it starts to seem simultaneously like a more manageable technology and a more powerful one. I’m now seeing APIs and opportunities for local MCP-based AI assistants everywhere.
Anyway, I haven’t included a live link to the project in this post because I’m currently paying a couple cents out of pocket for every Claude API call. (It was just easier in this rapid prototyping phase to put my own credit card down than to try to run this through the university’s purchasing office.) It’s also just generally not really ready for prime time. I haven’t done a ton of security or performance optimization, and I’m not really even sure what we'll do with it, though I could certainly imagine including a version of this for users who want it in the upcoming re-launch of Sourcery institutional accounts.
That said, if you’re interested in giving what I’m calling the “Sourcery Reference Interview Assistant for ArchivesSpace” (catchy, eh?) a spin, especially if you work in an archive that uses ArchivesSpace, just drop me an email, and I’ll be more than happy to send you a link.




Member discussion